O que é Deep Learning, seu desenvolvimento e quais aplicações
Embora o tema de hoje não seja propriamente uma novidade, ou algo recente, bem ao contrário disso na verdade, foi apenas nos últimos anos que os avanços e a aplicabilidade em situações quotidianas, reais e importantes, foram conseguidos e por essa razão, as discussões e o interesse gerado, tem aumentado muito.
Estamos falando do Deep Learning.
Antes de entrarmos no assunto, devemos salientar que não pretendemos esgotá-lo, nem mesmo tratá-lo de modo muito técnico, já que é extremamente amplo e os conceitos envolvidos, são bastante complexos e, portanto, mesmo um grande livro, ainda seria insuficiente para cobrir tudo sobre…
A nossa abordagem pretende tornar a sua compreensão possível mesmo aos mais leigos quando a questão é tecnologia.
O que é Deep Learning?
Deep Learning está intimamente relacionado com Machine Learning ou Aprendizado de Máquina e que consiste em “treinar” computadores para que sejam capazes de aprender por conta própria e usar tal aprendizado na realização de tarefas de modo semelhante aos humanos.
Essa possível definição apenas dá uma noção vaga do que se trata, mas ainda é insuficiente para permitir que aqueles que não sabem nada a respeito, possam idealizar o que é.
Como costumamos fazer em questões do tipo, vamos lançar mão de algumas analogias e exemplos, para explicar os conceitos envolvidos e que são fundamentais para sua compreensão.
Traduzido literalmente, Deep Learning é aprendizado profundo e por termos afirmado sua estreita relação com Machine Learning, assunto já tratado em nosso blog, você não errará em deduzir que é aprendizado de máquina de forma mais profunda ou avançada.
Pense no processo de aprendizado humano e para isso, é necessário voltar nossa observação aos dois primeiros anos de idade de uma criança e que corresponde à etapa da vida em que nossos cérebros mais se desenvolvem e também é quando somos apresentados aos conceitos mais básicos, como por exemplo, formatos das coisas, dos objetos que nos cercam.
Entre os muitos brinquedos com finalidade pedagógica, é bastante comum aquele que a criança tem que encontrar e encaixar um quadrado, um triângulo, um círculo e outras peças de formatos geométricos, em uma peça maior e vazada com as mesmas formas.
Ao observar as primeiras vezes em que a criança tenta, é comum vê-la tentando colocar peças que não correspondem aos formatos corretos. Às vezes elas podem até insistir em colocar o círculo na área do quadrado e demonstrar alguma chateação ou frustração por não conseguirem.
Mas quando têm sucesso, ficam felizes e a tendência é que nas próximas tentativas seja mais fácil, mais rápido, mais natural, até que não errem mais.
É exatamente assim com muitas das coisas que aprendemos ao longo da vida.
Os erros nos indicam que devemos tentar novamente e que aquele caminho que produziu o erro, aquele modo de fazer, não funciona. É preciso outro caminho, outro modo de fazer.
A repetição e as tentativas – as bem e as mal sucedidas – fornecem informações para nosso cérebro, que as armazena de forma que possam ser utilizadas futuramente em situações similares, sabendo o que produz um erro e um acerto.
Um mecânico automotivo, antes de aprender tudo o que sabe, poderia olhar para todas as peças de um motor desmontado e reagir exatamente como qualquer leigo, exceto que todas as peças também têm formatos e tamanhos que remetem ao brinquedo infantil, apenas que em variedade bem maior.
Mas tantas quantas vezes tenha sido necessário desmontar um motor ou parte dele para conserto e a observação das peças, faz com que ele seja capaz de analisar um virabrequim e tirar uma série de conclusões sobre o seu estado de desgaste, eventuais problemas e riscos de quebra, vida útil, etc, bem como o habilite a remontar tudo com base nas informações que seu cérebro acumulou.
Pode-se dizer o mecânico que é hábil em identificar e reparar qualquer problema mecânico do automóvel, passou por um processo de aprendizado profundo (Deep Learning) de um humano.
Mas e como replicar isso para uma máquina?
Para compreender como é possível, precisaremos tratar de um conceito fundamental associado e que são as redes neurais.
O que são redes neurais?
São modelos usados em computação, que tentam reproduzir o papel desempenhado pela rede de neurônios que formam nosso sistema nervoso e nosso cérebro.
Os registros sobre o tema datam da década de 50 e por isso que mencionamos que o assunto está longe de ser algo novo.
Entre tudo o que a ciência já desvendou, o cérebro humano é dos objetos de estudo para o que ainda há mais perguntas do que respostas, mas a partir do que se sabe – e já se sabia nos anos 50 – algumas coisas tentaram ser replicadas em redes neurais.
O neurônio é a menor unidade – se é que podemos chamar assim – funcional do sistema nervoso. Na rede neural, o seu correspondente é o nó de rede e que tenta simular o mesmo papel.
Neurônios são especializados e agrupados em determinadas regiões do cérebro, de tal modo que há aqueles responsáveis pela fala, outros pela visão, pela memória e assim por diante, em relação a cada parte do nosso corpo.
Quando seu olho é exposto à uma imagem de fogo, a cena é transmitida pelo nervo ótico – o qual contém neurônios – até o cérebro. Nele o que foi visto, é identificado pelos neurônios responsáveis pela visão e muitas informações relacionadas ao aprendizado e que ficaram armazenadas em diversos neurônios, são “recuperadas”.
Dependendo do contexto e de outras coisas no ambiente, como por exemplo, a fonte do fogo, você sabe que pode colocar a panela sobre o fogo, ou quem sabe o espeto do churrasco, ou ainda que tem que procurar um extintor de incêndio, entre uma lista bastante extensa de outras possíveis reações.
Sabe também que pode-se queimar e, portanto, precisa ter cuidado.
Tudo isso e o que mais se souber sobre o fogo, é informação que foi acumulada por repetição, por aprendizado e até por erros, nas vezes em que você teve queimaduras e lembra-se do quão doloroso pode ser e que está armazenado em vários neurônios.
Guardadas as devidas proporções e o fato de que não é possível reproduzir o funcionamento e capacidade exata do neurônio, o nó de uma rede neural tem o mesmo papel.
Voltemos ao nosso exemplo de uma chama de fogo. Tudo o que pode nos vir à mente a partir da imagem, é resultado das sinapses e que são as conexões entre os neurônios, pelas quais passam impulsos elétricos, “transportando” as informações armazenadas sobre o fogo, em cada neurônio.
São essas conexões que permitem que a informação armazenada nos neurônios da memória, façam-nos lembrar das vezes que sofremos queimaduras e o quanto isso pode doer. O paralelo desse tipo de aprendizado em machine learning, é o aprendizado por reforço.
Para que os cerca de 86 bilhões de neurônios existentes em um cérebro, não tenham todos que “trabalhar”, somente os especializados e responsáveis por coletar a informação, armazenar e proporcionar uma saída ou resposta para a situação, é que entram em ação, conectando-se por algumas das aproximadas 125 trilhões de sinapses existentes entre todas as células nervosas.
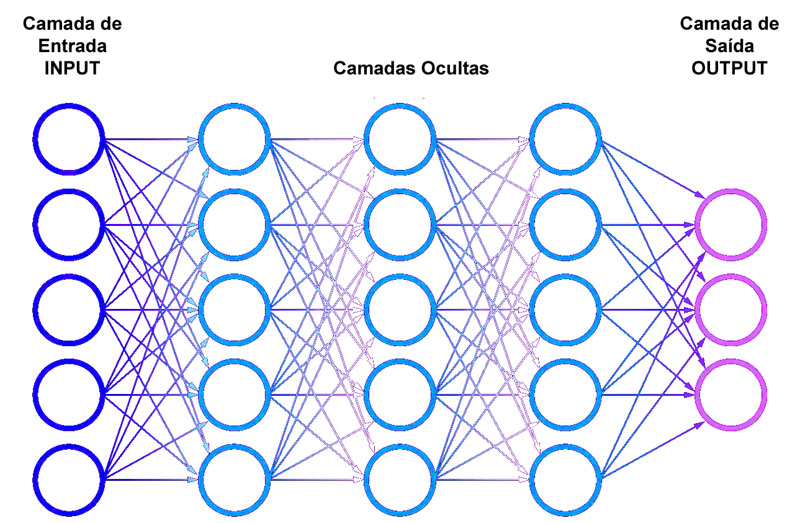
A rede neural tenta imitar essa estrutura toda, de tal modo que os nós são dispostos em camadas, sendo que os nós de cada camada estão conectados entre si e com os nós das outras camadas, de modo semelhante às sinapses cerebrais.
A primeira camada é a de entrada (input) e é análoga ao nervo ótico, porque é ela a responsável por “alimentar” a segunda camada – que é oculta – que corresponderia à memória do nosso exemplo e que tem registrada a informação de que pode queimar e produzir dor. Essa camada passa a informação para a terceira, que é de saída (output) e a decisão ou conclusão, de que é preciso tomar cuidado.
Todo esse fluxo dos dados é submetido à rede neural tal como ocorre no cérebro, coletando repetitivamente as informações, realizando treinamento supervisionado e por reforço, armazenando os resultados para cada interação e dessa forma capacitando a rede a aprender.
Por fim, novamente como na rede de neurônios do nosso sistema nervoso, os nós da rede neural são dispostos em diversas camadas mais ou menos como as diferentes regiões do cérebro, em que cada camada é responsável por dar um tratamento algorítmico aos dados recebidos por outros nós.
Um algoritmo é um conjunto de instruções e verificações lógicas para executar algo. Uma receita de bolo, é um exemplo de tipo de algoritmo. Um tutorial de como configurar uma conta de e-mail, também é.
A diferença é que os algoritmos das redes neurais são bem mais sofisticados.
Logo, dependendo da saída ou do resultado de uma camada que aplicou o algoritmo às informações, outras camadas não precisam “trabalhar”, da mesma forma que as regiões do cérebro que não processam nada diante da imagem do fogo.
Tudo isso para dizer que quanto mais camadas tem uma rede, mais profunda ela é e capaz de produzir aprendizados diferentes e por essa razão chama-se Deep Learning.
Desenvolvimento do Deep Learning
Agora que você já sabe o que é Deep Learning, a sua dependência das redes neurais e que boa parte de todos esses conceitos já são conhecidos há décadas, deve estar se perguntando porque somente nos últimos anos tem sido explorado, certo?
Implantar uma rede de aprendizado profundo para aplicações práticas, requer investimento pesado e muito poder computacional.
Entre tudo o que a Internet acarretou, como o desenvolvimento de tecnologia associada, o volume de dados produzido, a ciência de dados e o Big Data, data center e cloud computing, fizeram com que tenhamos disponível o poder de processamento exigido por redes neurais de muitos nós e camadas.
Mas não foi só. A indústria de games e a exigência de processamento de vídeo cada vez maior, foi um contributo importante, uma vez que os processadores gráficos são mais poderosos para cálculos matemáticos, razão pela qual também placas de vídeo costumam ser usadas para minerar criptomoedas.
Para que serve ou quais aplicações do Deep Learning?
Se fomos eficientes em fazê-lo compreender o que é aprendizado profundo, deve também ter ficado fácil compreender que ele é a base do desenvolvimento da Inteligência Artificial.
Simplificadamente, a inteligência humana baseia-se na coleta de informações, na sua classificação por meio de filtros e no seu armazenamento, no aprendizado e na combinação de tudo para então encontrar soluções e criar coisas novas.
Exatamente o que os pesquisadores da área estão obtendo sucesso em reproduzir por meio do Deep Learning!
Em termos mais práticos, muitas aplicações já fazem parte do nosso quotidiano e já nos beneficiamos delas.
A Siri da Apple e a Cortana da Microsoft, são exemplos de sistemas baseados no aprendizado profundo.
Alguns dos melhores serviços de filtragem de SPAM, usam o aprendizado profundo para aprender a reconhecer os padrões existentes em mensagens de correio eletrônico e assim permitir apenas e-mails legítimos na sua caixa de entrada.
Ao entrar em contato com algumas empresas, os mais sofisticados assistentes virtuais inteligentes entre suas capacidades, está o reconhecimento de linguagem natural, que é o modo como as pessoas falam, para oferecer um atendimento tão próximo quanto possível de um atendente humano.
O reconhecimento facial que permite identificar usuários em fotos postadas no Facebook, ou ainda em alguns sistemas de segurança biométrica, também valem-se do Deep Learning.
As sugestões de filmes que aparecem quando você acessa e clica em “quem está assistindo” no Netflix, baseiam-se no aprendizado do sistema com base no que você assistiu, no que incluiu na sua lista e o que marcou como gostei ou não.
Os carros autônomos e mesmo os que estão quase lá, como os modelos da Tesla, que já são capazes de identificar outros veículos, pedestres, ciclistas, se você está cansado e se está saindo da faixa, entre outras coisas, apoiam-se em um sistema que faz uso massivo de redes neurais e aprendizado profundo.
Quando por exemplo, usa o Google Lens para tentar identificar uma planta ou mesmo um lugar, a imagem é submetida a diferentes camadas e algoritmos capazes de entregar uma página de resultados, tal qual uma pesquisa tradicional no popular site de buscas.
No post sobre Inteligência Artificial, mencionamos o exemplo do AlphaGo, que derrotou por um placar de 4x1, o campeão mundial do jogo de tabuleiro, Go. A versão seguinte, programada apenas com as regras do jogo, treinou contra si mesma inúmeras vezes, retendo os movimentos e estratégias que deram bons resultados, enfrentou a versão anterior e venceu por 100x0!
Mas uma recente polêmica, caracteriza o poder e o que podemos alcançar com Deep Learning…
GPT-3 da OpenAI vs Google
Em 2020 o mundo ficou estarrecido com a capacidade apresentada pelo GPT-3 para processar linguagem natural.
Criado pelo OpenAI, um laboratório de pesquisa com sede em San Francisco, o modelo baseado em Deep Learning fez uso de 175 bilhões de parâmetros para treinamento, boa parte compostos por textos de milhares de livros e por muitos conteúdos da Internet, para assim ser capaz de utilizar as palavras para produzir não apenas frases, mas textos inteiros.
Mas não quaisquer textos. Ao lê-los, são plenamente compreensíveis, lógicos, sem erros gramaticais e acima de tudo, parecem ter sido escritos por pessoas. Na verdade, até melhores do que muitos humanos conseguem produzir.
Bem, todos os que têm dificuldades em produzir conteúdo para seu blog ou qualquer site de conteúdo, devem ter ficado animados e estão querendo saber como usar o GPT-3, não é mesmo?
É bom reconsiderar…
Primeiro porque fala-se que a OpenAI já investiu mais de 10 milhões de dólares no seu desenvolvimento e outra boa quantia para mantê-lo, ou seja, não é acessível para muitos.
Mas a segunda e principal razão, é que o Google já se pronunciou a respeito, dizendo que conteúdo de sites que sejam produzidos por Inteligência Artificial ou recursos como o GPT-3, vão contra suas políticas de monetização. Mais ainda, serão classificados como SPAM.
Em outras palavras, se o site em questão for monetizado, pode ficar sem um tostão. O posicionamento para buscas orgânicas, vai despencar ou mesmo nem aparecerá nas SERPs.
Vale lembrar que o próprio Google também faz uso do Deep Learning para processamento de linguagem natural e que está em uso no Google BERT para entregar melhores resultados nas buscas dos usuários em seu mais popular serviço – a página de buscas.
A diferença é que se o GPT-3 usou 175 bilhões de parâmetros para treinamento, o Switch Transformers do Google, baseou-se em 1,6 trilhão deles!
Polêmicas sobre Deep Learning e IA
Aqueles que assim como nós são entusiastas da tecnologia e de tudo o que ela proporciona, fascinam-se facilmente com o universo de desdobramentos que o Deep Learning e por consequência a Inteligência Artificial podem trazer às nossas vidas.
Mas por outro lado muitas polêmicas, discussões e movimentos têm surgido no sentido de senão frear o desenvolvimento de tudo o que está relacionado, levantar questões éticas e dúvidas quanto à própria segurança e o futuro humano diante de máquinas, as quais já não há dúvida que podem suplantar-nos em diferentes áreas.
O próprio futuro da Internet, sob o ponto de vista da regulação global e das questões que precisam ser discutidas, como a privacidade, a segurança, ou os impactos ambientais. O poder de processamento requerido pelos maiores modelos de aprendizado profundo, significam consumo energético, calor e emissão de carbono e que também é um problemas dos data centers.
Há ainda os que defendem que governos e sociedade como um todo, precisam pensar e implantar políticas que visem qualificar e capacitar todo um contingente de pessoas que vai ver seus empregos sendo “roubados” pela tecnologia.
Não há dúvida que assim como tudo na vida, os avanços também trazem consequências negativas, sendo necessário considerar com profundidade seus possíveis impactos, com o perdão do trocadilho!
Conclusão
O Deep Learning está cada dia mais presente nas mais diversas situações, provendo soluções inteligentes e eficazes para empresas e usuários finais.