Tudo o que você precisa saber sobre codificação de caracteres
Quando você instala o Windows, o Linux ou qualquer outro sistema no seu notebook ou desktop, é preciso escolher o idioma que você fala e que será o padrão utilizado em tudo o que você fizer, certo?
Mas existem vários idiomas e também diferentes alfabetos, como o árabe ou o cirílico. Como os computadores entendem todas essas diferenças e variações?
Isso só é possível, graças à codificação de caracteres.
Quer saber mais a respeito? O que é e sua história? Por que é importante? É sobre esse tipo de questões que falaremos no bate-papo de hoje...
O que é codificação de caracteres?
A codificação de caracteres é um conjunto de padrões fundamentais da computação moderna, pois através dela é feito o mapeamento do universo de símbolos letras, números e caracteres especiais dos mais diversos idiomas e alfabetos, para valores numéricos correspondentes e que são armazenados e manipulados por sistemas e computadores.
É isso que permite que os computadores processem e exibam textos diferentes, nos mais variados idiomas.
Em outras palavras, podemos afirmar que a codificação de caracteres funciona como uma espécie dicionário, traduzindo a variedade de símbolos humanos na única linguagem que os computadores “entendem”, que são os números binários.
Sem essa “tradução”, os computadores, os sistemas operacionais e os programas, não seriam capazes de interpretar a grande variedade de textos que as pessoas usam na comunicação diária, mundo afora.
Genericamente, em um sistema operacional, a codificação é usada para:
-
Quando você cria um documento em um editor de texto, as palavras contidas no texto não são salvas como nós as escrevemos, mas por meio dos seus respectivos códigos e de acordo com a codificação escolhida. Por exemplo, a codificação padrão utilizada pelo Microsoft Word para salvar documentos, é o Unicode, pois suporta a maioria dos caracteres em diversos idiomas;
-
Os nomes de arquivos e diretórios são representados usando codificações de caracteres. A configuração apropriada da codificação é crucial para garantir que os nomes de arquivos sejam exibidos corretamente e sejam compatíveis entre diferentes sistemas operacionais;
-
Quando você digita no teclado ou lê dados de um arquivo, os sistemas operacionais precisam interpretar esses caracteres. A codificação de caracteres é usada para converter os dados numéricos em texto legível;
-
A escolha das configurações regionais e idiomas afeta a codificação de caracteres usada para exibir menus, mensagens e outros elementos de interface, permitindo que as pessoas nos mais diferentes países possam ter acesso aos recursos de um mesmo sistema operacional;
-
Os navegadores Web e, portanto, o que fazemos na Internet, também depende da codificação de caracteres. Os protocolos de Internet, como HTTP, SMTP e FTP usam codificações específicas para transmitir dados de texto.
História da codificação de caracteres
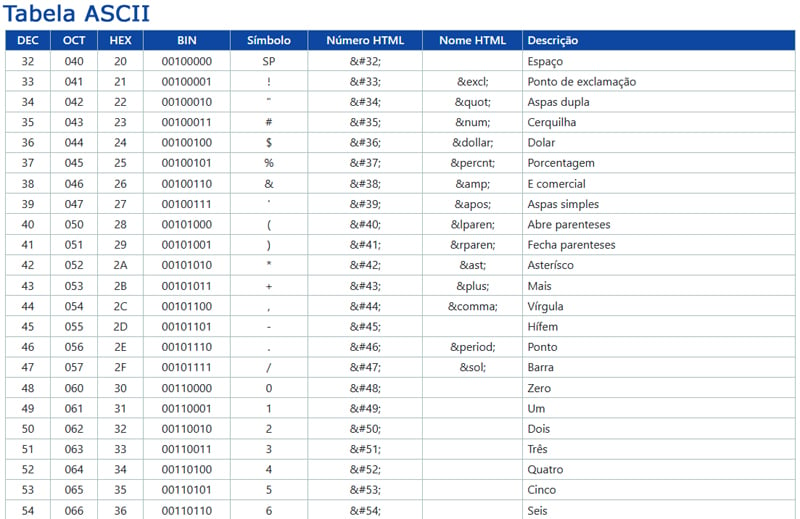
A codificação de caracteres, no escopo do seu uso em computação, surgiu na década de 1960, com o desenvolvimento do código ASCII (American Standard Code for Information Interchange). O ASCII foi criado para padronizar a representação de caracteres em computadores, permitindo a troca de informações entre diferentes sistemas.
Mas como se pode imaginar, o ASCII sendo um padrão norte-americano, não contempla caracteres acentuados, por exemplo.
O ASCII foi lançado em 1963 e previa a utilização de um código de 8 bits para representar letras e caracteres especiais como o “*” ou o “+” e os números, porém apenas 7 bits são utilizados, sendo que o primeiro bit é sempre zero.
Em 1964, foi criado o EBCDIC (Extended Binary Coded Decimal Interchange Code), um código de 8 bits usado principalmente em sistemas IBM.
Mas foi apenas em 1980, que ocorreu o desenvolvimento de diversos conjuntos de caracteres para diferentes idiomas, como ISO-8859-1, para o alfabeto latino ocidental e o ISO-8859-5, para o cirílico.
No caso, o ISO-8859-1 foi de particular interesse no Brasil, pois contempla os caracteres acentuados e o “Ç”, ausentes no ASCII. Diferentemente do padrão norte-americano, ele usa todos os 8 bits e, portanto, tem um total de 256 possibilidades. Ou seja, mais do que o ASCII, que por usar apenas 7 bits, oferece somente 128 possibilidades de caracteres e códigos especiais, como a tecla “ESC” ou “BACK SPACE”.
A necessidade de suportar múltiplos sistemas de escrita, incluindo os alfabetos do leste-asiático, exigiu uma abordagem diferente e mais ampla para a codificação de caracteres e que fez com que em 1991, ocorresse a publicação de um padrão que visava unificar a representação de caracteres em todos os idiomas, o Unicode, o qual contempla mais de cem mil caracteres e possui um código inteiro único para cada um deles.
Ao contrário dos sistemas anteriores, o Unicode não é um sistema baseado em um tamanho fixo de bits. Ele define caracteres e seus identificadores únicos e que podem ter 21 bits cada.
O UTF-8 foi criado em 2 de setembro de 1992 por Ken Thompson e Rob Pike, durante um almoço em um restaurante de Nova Jersey. No dia seguinte, eles implementaram o UTF-8 no sistema operacional Plan 9, pois na época, existiam diversos sistemas de codificação de caracteres incompatíveis entre si, o que dificultava a troca de dados entre diferentes sistemas.
Na virada do século e com o avanço comercial da Internet a passos largos, gradativamente o UTF-8 se consagrou como o padrão mais usado em sites e aplicações Web.
A codificação de caracteres continua a evoluir com o tempo, com novos conjuntos de caracteres sendo desenvolvidos para atender às necessidades mais diversas.
Por que é importante a codificação de caracteres de um site ou aplicação?
A escolha da codificação de caracteres é crucial no desenvolvimento de um site ou aplicação por diversos motivos:
1. Compatibilidade
Se a codificação utilizada não for compatível com o sistema do usuário, o texto pode ser exibido incorretamente, com caracteres estranhos ou ilegíveis, tornando o conteúdo inutilizável.
Além disso, a escolha adequada garante que o site ou aplicativo funcione em diferentes sistemas e plataformas, sem problemas de compatibilidade.
2. Acessibilidade
A definição correta é o que garante que o site ou aplicativo seja acessível a usuários em vários idiomas, incluindo aqueles com acentos e caracteres especiais ou exclusivos de um alfabeto em particular.
Também é por conta dela, que as informações possam ser interpretadas por tecnologias assistivas, como leitores de tela, permitindo a acessibilidade do conteúdo a pessoas com deficiência visual.
3. SEO
Outro fator essencial, é a correta indexação do conteúdo do site pelos mecanismos de busca e garantindo que o trabalho de SEO (Search Engine Optimization) produza os resultados pretendidos. Um problema na codificação, significa um problema na indexação do respectivo conteúdo.
Não fosse o SEO razão suficiente, o suporte a diferentes idiomas aumenta a visibilidade do site para usuários de todo o mundo.
4. Segurança
A codificação de caracteres está intimamente relacionada à segurança de sites e sistemas diversos, por algumas das seguintes razões:
-
Validação de dados de entrada – a codificação correta dos dados de entrada é crucial para evitar invasões e ataques de injeção, como SQL injection ou XSS (Cross-Site Scripting). Se os dados de entrada não forem tratados adequadamente, caracteres especiais ou maliciosos podem ser interpretados erroneamente, comprometendo a segurança do sistema;
-
Codificação de dados de saída – a codificação adequada dos dados de saída também visa evitar vulnerabilidades. Ao exibir informações em uma página da web, por exemplo, é essencial garantir que caracteres especiais sejam corretamente codificados para evitar ataques XSS;
-
Autenticação – é de especial relevância ao lidar com senhas e credenciais, para que os dados recebam o tratamento correto antes de serem armazenadas no banco de dados;
-
Tratamento de erros e logs do sistema – a codificação incorreta de mensagens de erro ou logs do sistema tornam inúteis informações que devem ser precisas;
-
Proteção de Dados – a criptografia é uma forma de codificação que protege dados sensíveis / confidenciais e, portanto, escolha correta dos algoritmos de criptografia e de codificação, é crucial para sua proteção.
5. Desempenho
Como vimos que diferentes sistemas de codificação usam métodos diferentes e também têm tamanhos diferentes, é de se imaginar que o desempenho também seja afetado por essas diferenças.
A escolha da codificação adequada pode otimizar o uso de espaço de armazenamento, especialmente para sites e aplicativos com grande quantidade de texto.
Uma codificação eficiente pode melhorar a velocidade de carregamento do site ou aplicativo
Por fim, mas não menos importante, devemos salientar que a escolha da codificação de caracteres a ser utilizada sempre deve considerar cenários, como:
-
Idioma do documento / arquivo – algumas codificações de caracteres são mais adequadas para determinados idiomas. Por exemplo, o ASCII é adequado para o inglês, mas não para idiomas com acentos ou outros caracteres especiais, como o “Ç”;
-
Público-alvo – idiomas e caracteres utilizados pelo público-alvo do site / aplicação;
-
Sistema operacional – diferentes sistemas operacionais podem ter suporte para diferentes codificações de caracteres;
-
Aplicação – alguns aplicativos podem ter requisitos específicos de codificação de caracteres, justamente em função dos caracteres que são exibidos / utilizados;
-
Desempenho – demanda de armazenamento e velocidade de carregamento;
-
Interoperabilidade – quando há a necessidade de comunicação e o compartilhamento de informações entre diferentes sistemas e softwares.
Por que o UTF-8 é usado na Internet?
Se você já pesquisou a respeito, deve ter notado que entre os mais diferentes padrões existentes, quando o assunto é o desenvolvimento de sites ou aplicações Web, é quase unânime a recomendação pelo uso do UTF-8.
Entre as principais razões para sua adoção, podemos citar:
-
Compatibilidade – o UTF-8 foi projetado para ser compatível com o ASCII e que era o conjunto de caracteres básico usado nos primeiros computadores, bem como vários outros sistemas de codificação;
-
Universal – o UTF-8 tem uma representação de caracteres considerada universal, suportando todos os caracteres Unicode, incluindo símbolos, emojis e caracteres de múltiplos idiomas;
-
Otimizado – para caracteres ASCII, o UTF-8 usa apenas um byte, economizando espaço em arquivos e transmissões de dados;
-
Nível de adoção – quase todos os sistemas operacionais, navegadores e aplicativos modernos, têm suporte para o UTF-8;
-
Padrão Web – seu uso é recomendado pelo W3C e desde então se tornou o padrão dominante para páginas da web, contabilizando mais de 98% de todas as páginas na Web;
-
Segurança – evita problemas de exibição incorreta de caracteres, o que é especialmente relevante em aspectos envolvendo a segurança do site;
-
Uniformidade – garante que o mesmo conteúdo seja exibido corretamente em diferentes dispositivos e plataformas.
Conclusão
A escolha da codificação de caracteres, influencia a segurança, a eficiência e o funcionamento de sistemas e sites na Internet, por parte dos usuários.